
From Airbnb to Zendesk, a ton of really great apps were built using the Ruby programming language and the Rails web framework. Albeit a less popular option than other front-end frameworks such as React, Angular, and Vuejs, Rails still holds substantial merit in modern software development.
Ruby on Rails (RoR) is open-source, well-documented, fiercely maintained, and constantly extended with new Gems — community-created open-source libraries, serving as “shortcuts” for standardized configuration and distribution of Ruby code.
Rails is arguably the biggest RoR gem of them all — a full-stack server-side web application framework that is easy to customize and scale.
What is Rails? A Quick Refresher
Rails was built on the premises of Model-View-Controller (MVC) architecture.
This means each Rails app has three interconnected layers, accountable for a respective set of actions:
- Model: A data layer, housing the business logic of the app
- Controller: The “brain center”, handling application functions
- View: Defines graphical user interfaces (GUIs) and UI performance
In essence, the model layer establishes the required data structure and contains codes needed to process the incoming data in HTML, PDF, XML, RSS, and other formats. The model layer then communicates updates to the View, which updates the GUI. The controller, in turn, interacts both with models and views. For instance, when receiving an update from a view, it notifies the model on how to process it. At the same time, it can update the view too on how to display the result for the user.
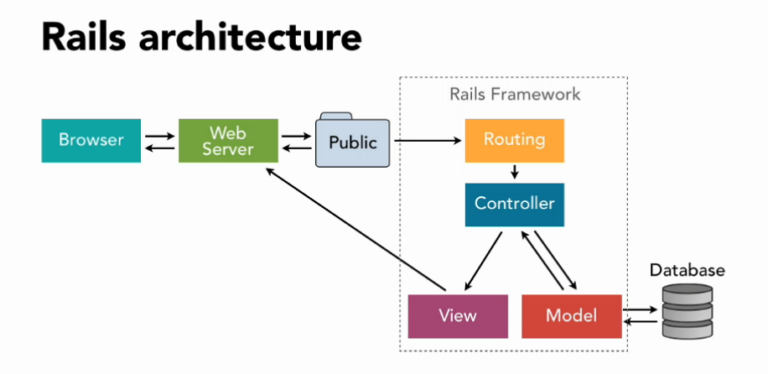
(Basic Rails app architecture. Image source: Medium)
The underlying MVC architecture lends several important advantages to Rails:
- Parallel development capabilities — one developer can work on View, while others handle the model subsystem. The above also makes Ruby on Rails a popular choice for rapid application development (RAD) methodology.
- Reusable code components — controllers, views, and models can be packaged to share and reuse across several features with relative ease. When done right, this results in cleaner, more readable code, as well as faster development timelines. Also, Ruby on Rails is built on the DRY principle (don’t repeat yourself), prompting more frequent code reuse for monotonous functions.
- Top security — the framework has a host of built-in security-centric features such as protection against SQL injections and XSS attacks, among others. Moreover, there’s plenty of community-shipped gems addressing an array of common and emerging cybersecurity threats.
- Strong scalability potential — there’s a good reason why jumbo-sized web apps such as GitHub, Twitch, and Fiverr are built on Rails. Because it scales well when the overall app architecture and deployment strategy are done right. In fact, one of the oldest Rails apps, Shopify, scales to processing millions of requests per minute (RPM).
In spite of this, many Rails guides still make the arbitrary claim that Rails apps are hard to scale. Are these true? Not entirely, as this post will showcase.
3 Common Problems With Scaling Rails Apps
The legacy lore once told that scaling Rails apps is like passing a camel through the eye of a needle — exasperating and exhausting.
To better understand where these concerns are coming from, let’s first recap what scalability is for web apps.
Scalability indicates the application’s architectural capability to handle more user requests per minute (RPM) in the future.
The keyword here is “architecture”, as your choices of infrastructure configuration, connectivity, and overall layout are determinants to the entire system’s ability to scale. The framework(s) or programming languages you use will only have a marginal (if any) impact on the scalability.
In the case of RoR, developers, in fact, get a slight advantage as the framework promotes clean, modular code that is easy to integrate with more database management systems. Moreover, adding load balancers for processing a higher number of requests is relatively easy too.
Yet, the above doesn’t fully eradicate scaling issues on Rails. Let’s keep it real: any app is hard to scale when the underlying infrastructure is subpar.
Specifically, Ruby scaling issues often pop up due to:
- Poor database querying
- Inefficient indexing
- Lack of logging and monitoring
- Subpar database engine selection
- Sluggish caching
- Overly complex and spaghetti code
Over-Engineered App Architecture
RoR supports multi-threading. This means the Rails framework can handle concurrent processing of different parts of code.
On the one hand, multi-threading is an advance since it enables you to use CPU time wiser and ship high-performance apps.
At the same time, however, the cost of context switching between different threads in highly complex apps can get high. Respectively, performance starts lagging at some point.
How to Cope
By default, Ruby on Rails prioritizes clean, reusable code. Making your Rails app architecture overly complex (think too custom) indeed can lead to performance and scalability issues.
This was the case with Twitter circa 2007.
The team developed a Twitter UI prototype on Rails and then decided to further code the back-end on Rails too. And they decided to build a fully custom, novel back-end from scratch rather than modifying some tested components. Unsurprisingly, their product behaved weirdly and times and scaling it was challenging, as the team admitted in a presentation. They ended up with a ton of issues when partitioning databases because their code was overly complex and bloated.

Image Source: SlideShare
Interestingly, at the same time, another high-traffic Rails web app called Penny Arcade was doing just fine. Why? Because it had no funky overly-custom code, had clearly mapped dependencies, and hailed well with connected databases.
Remember: Ruby supports multi-processing within apps. In some cases, multi-process apps can perform better than multi-thread ones. But the trick with processes is that they consume more memory and have more complex dependencies. If you inadvertently kill a parent process, children processes will not get informed about the termination and thus, turn into sluggish “zombie” processes. This means they’ll keep running and consume resources. So watch out for those!
Suboptimal Database Setup
In the early days, Twitter had intensive write workloads and poorly organized read patterns, which were non-compatible with database sharding.
At present, a lot of Rails developers are still skimming on coding proper database indexes and triple-checking all queries for redundant requests. Slow database queries, lack of caching, and tangled database indexes can throw any good Rails app off the rails (pun intended).
Sometimes, complex database design is also part of deliberate decisions, as was the case with one of our clients, PennyPop. To store app data, the team set up an API request to the Rails application. The app itself then stores the data inside DynamoDB and sends a response back to the app. Instead of ActiveRecord, the team created their own data storage layer to enable communication between the app and DynamoDB.
But the issue they ran into is that DynamoDB has limits on how much information can be stored in one key. This was a technical deal-breaker, but the dev team came up with an interesting workaround — compressing the value of the key to a payload of base64 encoded data. Doing so has allowed the team to exchange bigger records between the app and the database without compromising the user experience or app performance.
Sure, the above operation requires more CPU. But since they are using Engine Yard to help manage and optimize other infrastructure, these costs remain manageable.
How to Cope
Granted, there are many approaches to improving Rails database performance. Deliberate caching and database partitioning (sharding) is one of the common routes as your app grows more complex.
What’s even better is that you have a ton of great solutions for resolving RoR database issues, such as:
- Redis — an open-source in-memory data structure store for Rails apps.
- ActiveRecord — a database querying tool standardizing access to popular databases with built-in caching capabilities.
- Memcached — distributed memory caching system for Ruby on Rails.
The above three tools can help you sufficiently shape up your databases to tolerate extra-high loads.
Moreover, you can:
- Switch to UUIDs over standard IDs for principle keys as your databases grow more complex.
- Try other ORM alternatives to ActiveRecord when your DBs get extra-large. Some good ones include Sequel, DataMapper, and ORM Adapter.
- Use database profiling gems to diagnose and detect speed and performance issues early on. Popular ones are rack-mini-profiler, bullet, rails_panel, etc.
Insufficient Server Bandwidth
The last problem is basic but still pervasive. You can’t accelerate your Rails apps to millions of RPMs if you lack resources.
Granted, with cloud computing, provisioning extra instances is a matter of several clicks. Yet, you still need to understand and account for:
- Specific apps/subsystems requirements for extra resources
- Cloud computing costs (aka the monetary tradeoff for speed)
Ideally, you need tools to constantly scan your systems and identify cases of slow performance, resources under (and over)-provisioning, as well as overall performance benchmarks for different apps.
Not having such is like driving without a speedometer: You rely on a hunch to determine if you are going too slow or deadly fast.
How to Cope
One of the lessons we learned when building and scaling Engine Yard on Kubernetes was that the container platform sets no default resource limits for hosted containers. Respectively, your apps can consume unlimited CPU and memory, which can create “noisy neighbor” situations, where some apps rack up too many resources and drag down the performance of others.
The solution: Orchestrate your containers from the get-go. Use Kubernetes Scheduler to right-size nodes for the pods, limit maximum resource allocation, plus define pod preemption behavior.
Moreover, if you are running containers, always set up your own logging and monitoring since there are no out-of-the-box solutions available. Adding Log Aggregation to Kubernetes provides extra visibility into your apps’ behavior.
In our case, we use:
- Fluent Bit for distributed log collection
- Kibana + Elasticsearch for log analysis
- Prometheus + Grafana for metrics alerting and visualization
To sum up: The key to ensuring scalability is weeding out the lagging modules and optimizing different infrastructure and architecture elements individually for a greater cumulative good.
Scaling Rails Apps: Two Main Approaches
Similar to others, Rails apps scale in two ways — vertically and horizontally.
Both approaches have their merit in respective cases.
Vertical Scaling
Vertical scaling, i.e., provisioning more server resources to an app, can increase the number of RPMs. The baseline premises are the same as for other frameworks. You add extra processors, RAM, etc., until it is technically feasible and makes financial sense. Understandably, vertical scaling is a temp “patch” solution.
Scaling Rails apps vertically makes sense to accommodate linear or predictable growth since cost control will be easy too. Also, vertical scaling is a good option for upgrading database servers. After all, slow databases can be majorly accelerated when placed on better hardware.
Hardware is the obvious limitation to vertical scaling. But even if you are using cloud resources, still scaling Rails apps vertically can be challenging.
For example, if you plan to implement Vertical Pod Autoscaling (VPA) on Kubernetes, it accounts for several limitations.
During our experiments with scaling Ruby apps, we found that:
- VPA is a rather disruptive method since it busts the original pod and then recreates its vertically scaled version. This can cause much havoc.
- You cannot pair VPA with Horizontal Pod Autoscaling.
So it’s best to prioritize horizontal scaling whenever you can.
Horizontal Scaling
Horizontal scaling, i.e., redistributing your workloads across multiple servers, is a more future-proof approach to scaling Rails apps.
In essence, you convert your apps in a three-tier architecture featuring:
- Web server and load balancer for connected apps
- Rails app instances (on-premises or in the cloud)
- Database instances (also local or cloud-based)
The main idea is to distribute loads across different machines to obtain optimal performance equitably.
To effectively reroute Rails processes across server instances, you must select the optimal web server and load balancing solution. Then right-size instances to the newly decoupled workloads.
Load balancing
Load balancers are the key structural element for scale-out architecture. Essentially, they perform a routing function and help optimally distribute incoming traffic across connected instances.
Most cloud computing services come with native software load balancing solutions (think Elastic Load Balancing on AWS). Such solutions also support dynamic host port mapping. This helps establish a seamless pairing between registered web balancers and container instances.
When it comes to Rails apps, the two most common options are using a combo of web servers and app servers (or a fusion service) to ensure optimal performance.
- Web servers transfer the user request to your website and then pass it to a Rails app (if applicable). Essentially, they filter out unnecessary requests for CSS, SSL, or JavaScript components (which the server can handle itself), thus reducing the number of requests to the Rails app to bare essentials.
– Examples of Rails web servers: Ngnix and Apache.
- App servers are programs that maintain your app in memory. So that when an incoming request from a web server apps appears, it gets routed straight to the app for handling. Then the response is bounced back to the web server and, subsequently, the user. When paired with a web server in production, such a setup lets you render requests to multiple apps faster.
– Examples of app servers for Rails: Unicorn, Puma, Thin, Rainbows.
Finally, there are also “fusion” services such as Passenger App (Phusion Passenger). This service integrates with popular web servers (Ngnix and Apache) and brings in an app server layer — available for standalone and combo use with web servers.
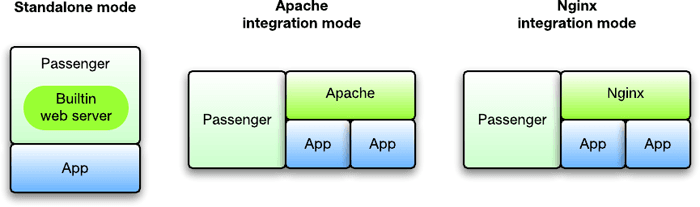
Image Source: Phusion Passenger
Passenger is an excellent choice if you want to roll out unified app server settings for a bunch of apps in one go without fiddling with a separate app server setup for each.
In a nutshell, the main idea behind using web and app servers is to span different rails processes optimally across different instances.
Pro tip: What we found when building our product is that AWS Elastic Load Balancer often doesn’t suffice. A major drawback is that ELB can’t handle multiple vhosts.
In our case, we went on with configuring an NGINX-based load balancer and configured auto-scaling on it to support ELB. As an alternative, you can also try HAProxy.
App Instances
The next step of scale-out architecture is configuring communication between different app instances, where your Rails workloads will be allocated.
App servers (Unicorn, Puma, etc.) help ensure proper communication between web servers and subsequently increase the throughput of requests processed per second. On Rails, you can allocate an app server to handle multiple app instances, which in turn can have separate “worker” processes or threads (depending on which type of app server service you are using).
It’s important, however, to ensure that different app servers can communicate well with the webserver. Rack interface comes in handy here as it helps homogenize communication standards between standalone app servers.
When it comes to configuring the right instances for containers, keep in mind the following:
- You have four variables to min/max CPU and min/max memory to regulate pod size
- Limit the resources using [minimum requirement + 20%] formula
- Use average CPU utilization and average memory utilization as scaling metrics
- Mind the timing. Pods and clusters take 4 to 12 minutes to scale up on Kubernetes.
P.S. If you don’t want to do the above guesswork every time you are building a new pod/cluster, Engine Yard comes with a predictive cluster scaling feature, which helps you scale your infrastructure just-in-time without ballooning the costs.
Database Scaling
Transferring databases to a separate server, used by all app instances, is one of the sleekest moves you can do to scale Rails apps.
First of all, this can be a nice exercise in segregating your data and implementing database replication for improving business continuity. Secondly, doing so can reduce the querying time since the request will not have to travel through multiple database instances where different bits of data are stored. Instead, it will go straight to a consolidated repository.
Thus, consider setting up a dedicated MySQL or PostgreSQL server for your relational databases. Then scrub them clean and ensure optimal instance size to save costs.
For example, AWS RDC lets you select among 18 types of database instances and codify fine-grain provisioning. Choosing to host your data in a cheaper cloud region can drive substantial cost savings (up to 40% at times!).
Here’s how on-demand hourly costs differ across AWS regions:
US East (Ohio)
- db.t3.small — $0.034 per hour
- db.t3.xlarge — $0.272 per hour
- db.t3.2xlarge — $0.544 per hour
US West (LA)
- db.t3.small — $0.0408 per hour
- db.t3.xlarge —$0.3264 per hour
- db.t3.2xlarge — $0.6528 per hour
Europe (Frankfurt)
- db.t3.small — $0.04 per hour
- db.t3.large — $0.16 per hour
- db.t3.2xlarge — $0.64 per hour
Asia Pacific (Seoul)
- db.t3.small —$0.052 per hour
- db.t3.large — $0.208 per hour
- db.t3.2xlarge — $0.832 per hour
Another pro tip: opt for reserved instances over on-demand when you can to further slash the hourly costs.
Caching
Database caching implementation is another core step to accelerating your Rails apps, especially when it comes to database performance. Given the fact that RoR comes with a native query caching feature that caches the result set returned by each query, it’s a shame not to profit from this!
Caching can help you speed up those slow queries. But prior to implementing, investigate! Once you’ve found the “offenders”, consider trying out different strategies such as:
- Low-level caching — works best for any type of caching to retrieve database queries.
- Redis cache store — lets you store keys and value pairs up to 512 MB in memory, plus provides native data replication.
- Memcache store — another easy-to-implement in-memory datastore with values limited at 1 MB. Supports multi-thread architecture, unlike Redis.
Ultimately, caching improves data availability and, by proxy, your application’s querying speed and performance.
Database sharding
Lastly, at some point in your database scaling journey, you’ll inevitably face the decision to shard your relational databases.
Data sharding means slicing your DB records horizontally or vertically into smaller chunks (shards) and storing them on a cluster of database nodes. The definitive advantage is that querying should now happen faster since a large database gets split in two and has twice more memory, I/O, and CPU to run.
The tradeoff, however, is that sharding can significantly affect your app’s logic. The scope of each query is now limited to either DB 1 or DB 2 — there’s no commingling. Respectively, when adding new app functions, you need to carefully consider how to access data across shards, how sharing relates to the infrastructure, and what’s the best way to scale out the supporting infrastructure without affecting the app’s logic.
To Conclude: Is There An Easier Solution to Scaling Rails Apps?
Scaling Rails apps is a careful balancing act of ensuring optimal instance allocation, timely resource, provisioning, and careful container orchestration. Keeping tabs on all the relevant metrics across a portfolio of apps and sub-services isn’t an easy task when done manually. And it shouldn’t be.
You can try Engine Yard Kontainers (EYK) — our NoOps PaaS autoscaling services for containerized apps. In essence, we act as your invisible DevOps team. You code your apps and deploy them to EYK, and we take over auto-scaling implementation, container orchestration, and other infrastructure right-sizing tasks from there.
Learn more about Engine Yard.